

Grammar base recognition is a technology used to create reliable voice commands. Closely related to Free Speech, it takes the solution further with specific intent comprehension thanks to a grammar-based design.
For additional information on the use of Grammar Editor, you can also refer to the Grammar Editor tutorial available on VDK Studio.
Main screen
-
Model details. This is an information panel. You can collapse it by clicking on the title area or directly through the arrow icon on the top-left corner. Modification of displayed properties and some others is possible through the Modify button on the right, which will open the model settings dialog.
-
Tab bar. The Editor tab is always enabled. Other tabs get enabled either when supported by the current grammar, or after a successful compilation.
-
BNF Editor. This is where you write the actual BNF code.
-
Toolbar. This changes content depending on the currently selected tab.
-
Save button: Saves the text in the editor to disk.
-
Compile: Starts a compilation request of the BNF into a compiled model.
-
Next Step: When enabled, brings you to the next possible step of work by selecting the right tab view.
-
-
Test Controls. Your model must already be compiled to access this panel. The microphone button is enabled if a default microphone input that’s compatible with the voice recognition format is detected.
-
Test Results. Before anything is recognized, instructions or recognition events will display here. Once a result has been found, its confidence and best hypothesis are displayed instead.
Tick “Stop after first result” checkbox: The test stops after the first result.
Untick “Stop after first result” checkbox: Possibility of having several results in a row until manually stopped.
Dynamic Data screen
-
Slots data. Slots are BNF rules that are filled at runtime. Here you can provide content that will be used during testing through the previously shown test interface.
Settings screen
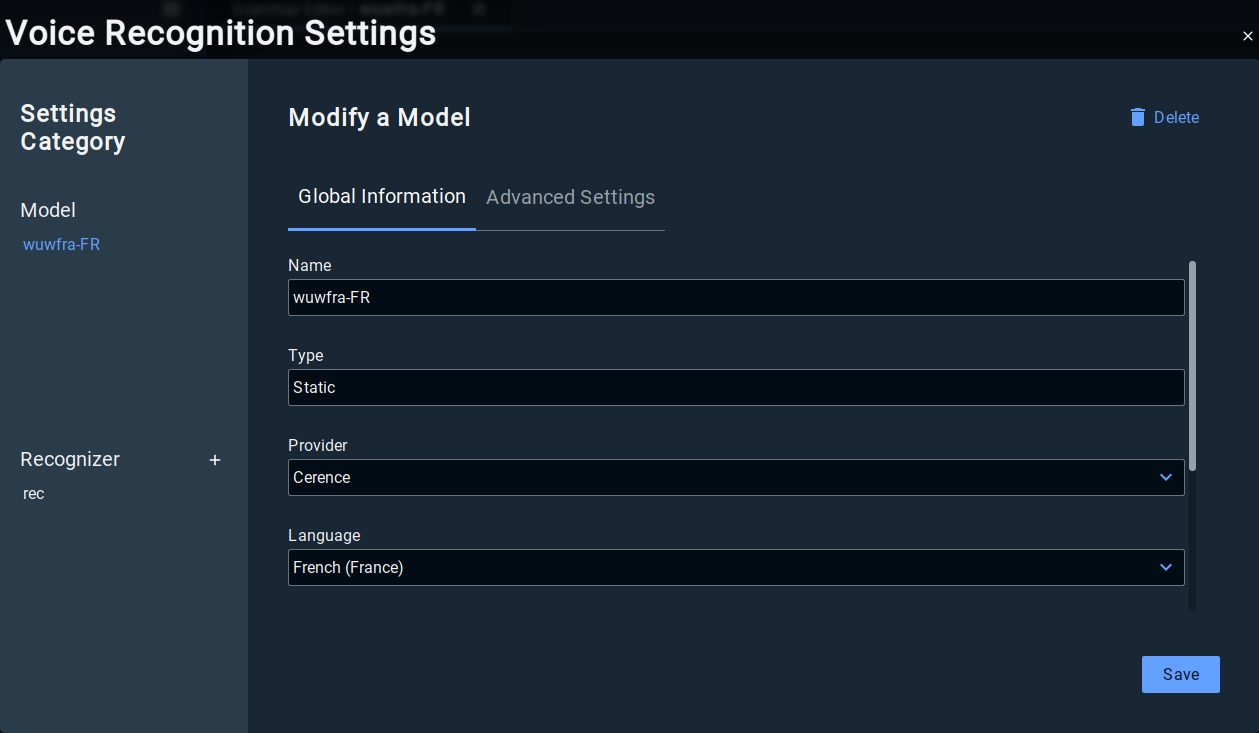
Models settings
-
Language. Select here the preferred language for your project.
-
Provider. Select the preferred technology provider for your project (Cerence, Voxygen, Vivoka).
Recognizer settings
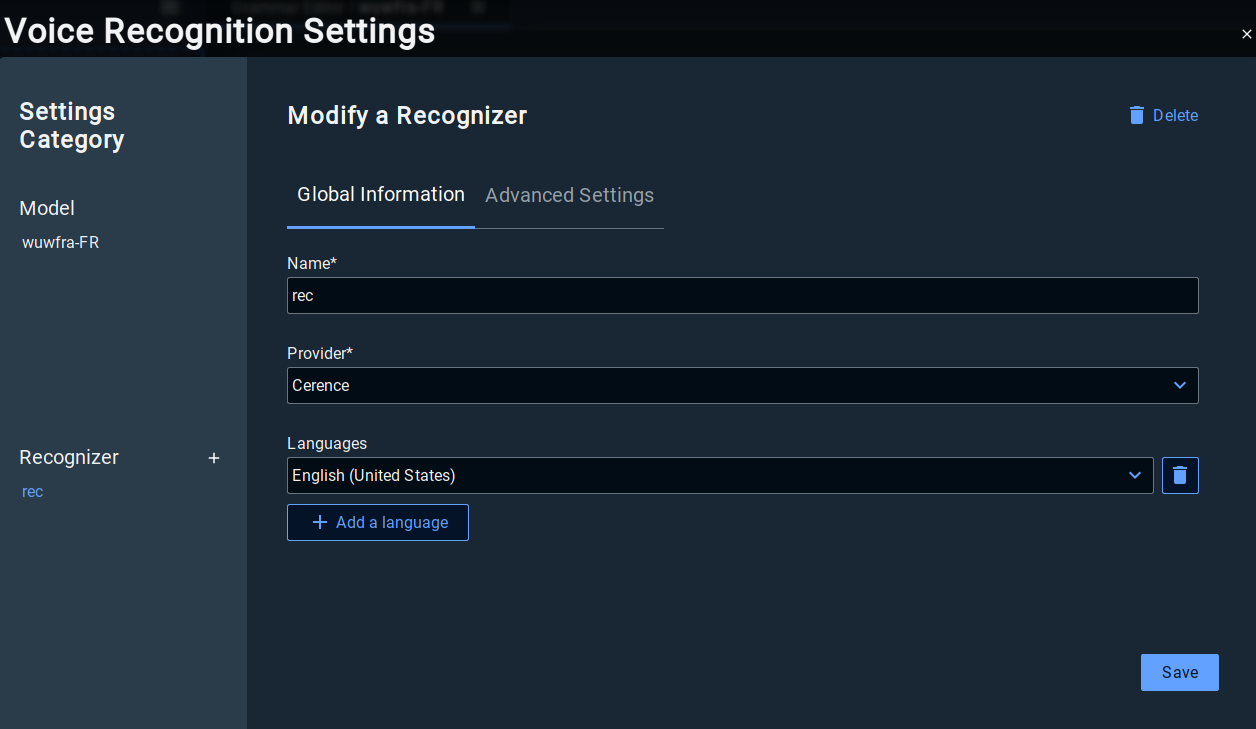
The recognizer’s settings will be generated automatically. You can update it if you want. It wont impact the Studio performance but it will change the recognizer generated in the configuration (vsdk.json).
-
Name. Select here the preferred language for your project.
-
Provider. Select the preferred technology provider for your project (Cerence, Voxygen, Vivoka).
-
Lang. Select the language used by the recognizer
Create a model
-
Go to the Playground.
-
In the voice recognition card, click on Add a model.
-
In the opened wizard with a choice, select grammar based.
-
You will next have to choose the name and the directory for your model.
-
In the next page, you will be prompted to choose a provider and then a language for your recognition engine.
-
You finish by clicking on Add to project.
Not all provider support the same set of languages. The list of languages will change accordingly.
Create a correct grammar
You can click on the model inside the Voice recognition card to open the editor.
When creating a grammar file you have a basic template generated.
If you don't know how to create a grammar please refer to the VSDK documentation grammar_formalism. A little explanation:
Grammar
Every grammar must have a header as the first line describing its format.
It's usually #BNF+EMV2.1;.
Then, you have to give your grammar a name using a statement as follow:
!grammar MyGrammarName;
Rules
Grammar uses rules to perform. You must at least use one rule as a start rule by writting !start <rule_name>.
The start rules will be the entry point for the ASR and how the speech should be recognized. You can call rules within rules, but not recursively.
To recognize text you simply have to write it.
Example:
<main>: I want a <drink>;
<drink>: tea | coffee;
Pronunciation
Some words can be difficult to detect because of regional pronunciations. You can use the !pronounce keyword with PRONAS to say that the word can be pronounced multiple ways.
PRONAS keyword is only available for the provider CSDK.
Example:
!pronounce "humour" PRONAS "humor" | PRONAS "humour";
If you want to precisely give a pronounciation for a word, you have the possibility to write the phonemes directly.
To help you build your phonetics, you can use the Phonetic Editor widget and then paste the result in here.
Example:
!pronounce "water" "wOtE0";
For now, only the L&H+ phonetic representation is supported.
You can use the phonetic editor for that.
Compile and test
Click on the compile button to generate a binary version of your grammar.
Once the compilation is done you can click on the Quick testing button to try the grammar.
You can see the result by looking at the confidence and result labels.