

What is a voice assistant?
A voice assistant is composed of 5 parts.
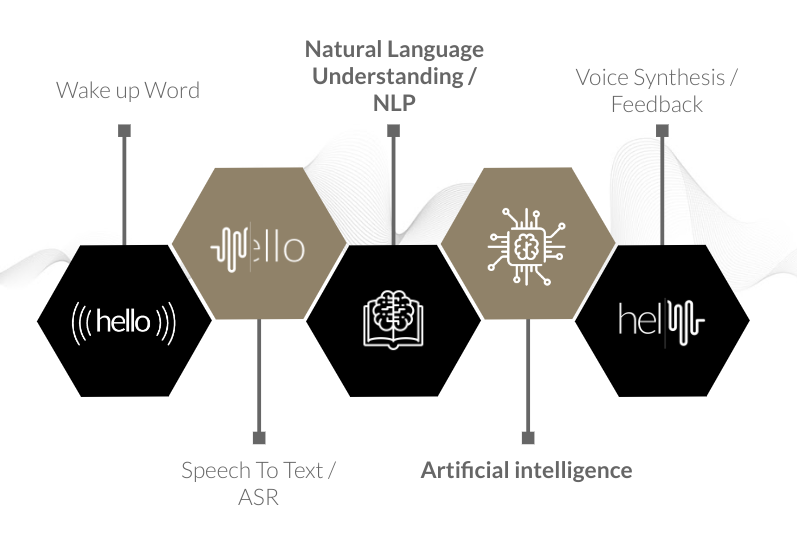
-
Wake-up Word (WuW)
Mainly used for Cloud recognition, the WuW allow a device to listen continously a microphone without sending data online nor wasting CPU calculation.
A good WuW is composed of at least 3 syllables, cut on consonants and based on non common words.
As an extra, it should sound like the same in every language you want to adress and you can use it as branding for your product. -
Speech to Text (STT)
This module transcribe audio frequencies from voice to text. There is 2 family of STT that can be resumed as:-
FreeSpeech: This system can transcribe a large vocabulary that need to be analysed by a NLP module.
-
Grammar based: This system will only transcribe the vocabulary it was setup for.
-
-
Natural Language Understanding (NLU)
Natural-language understanding (NLU) is the comprehension by computers of the structure and meaning of human language (e.g., English, Spanish, Japanese), allowing users to interact with the computer using natural sentences. -
Artificial Intelligence (AI)
This one is a melting pot of features in charges of executing the request of the user by calling API, editing database or anything else. -
Voice Synthesis
As a result for a voice command, a feedback should be given to the user. It can be a synthetized voice generate by a text to speech module.